Prints Out the Count of Records Read Spark
Spark Tutorial — Using Filter and Count
Since raw information can be very huge, one of the first mutual things to exercise when processing raw information is filtering. Information that is not relevant to the analysis shall exist discarded equally much equally possible in the get-go few steps. This would make the code less prone to errors, consumes less resource, and runs faster.
This tutorial will guide you how to perform basic filtering on your data based on RDD transformations.
Objectives
What you will learn includes
- How to read data from file to an RDD using
.textFile() - How to sample and print elements of an RDD using
.accept() - How to filter data using
.filter()with.contains() - How to use NOT with
.contains() - How to count the number of RDD elements using
.count()
Information regarding Spark setup and environment used in this tutorial are provided on this Spark Installation (another version in Thai here).
For absolute beginners, please also read Hello World programming on Spark if you take not.
Ok. Permit's get started.
The data
The first dataset that I will use throughout a number of my Spark tutorials is the results of football matches, which can be plant here.
For this tutorial, allow's take a wait at and download the English Premier League season 2016/2017. The data is a .csv file. It looks like this when being opened in a text editor, Sublime in this case.
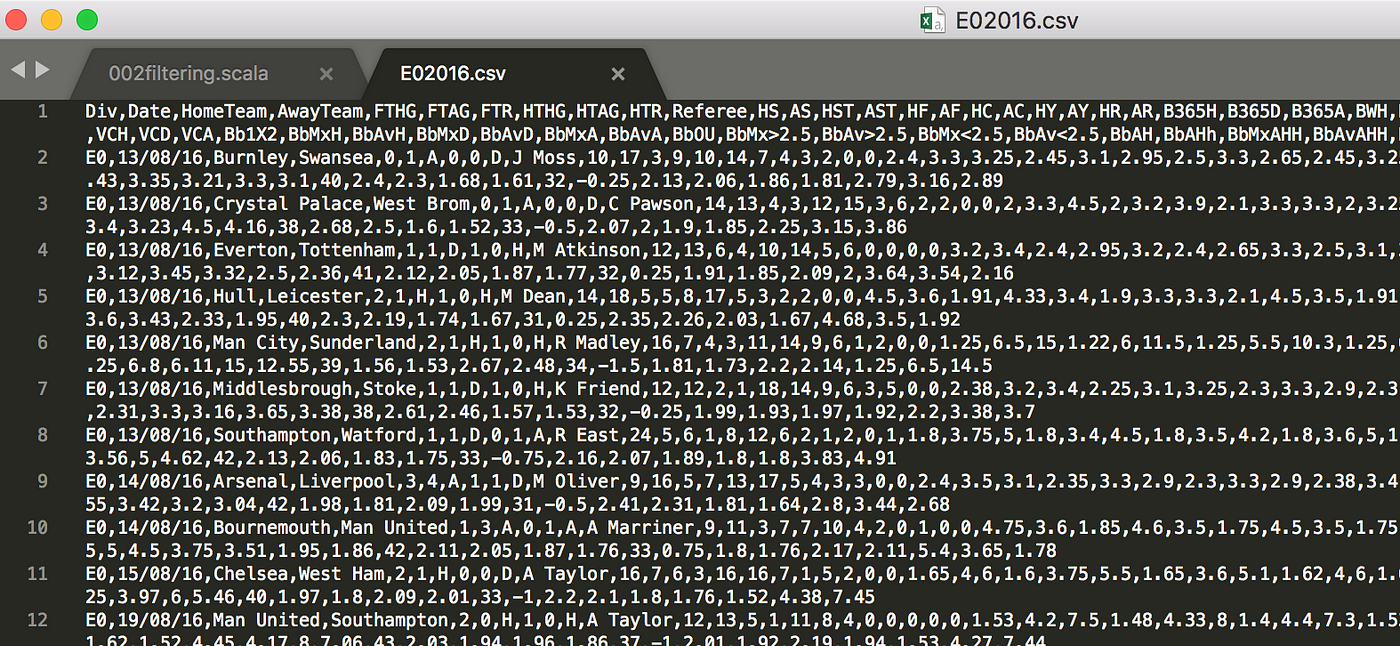
- The data contains a number of rows, 381 to exist exact, and each row contains several fields separated by commas.
- The first line contains the information of the header row. Information technology is no the actual data just rather the description of the information. The full description can be found here.
- Here I put some descriptions along with the kickoff dataset (the second line in the file)
Here are parts of the first data (from the second row)
E0,thirteen/08/16,Burnley,Swansea,0,i,A,0,0,D,J Moss,... Here are descriptions (with data) Div = League Division (E0)
Date = Match Date (dd/mm/yy) (thirteen/08/16)
HomeTeam = Home Team (Burnley)
AwayTeam = Away Squad (Swansea)
FTHG and HG = Full Time Home Squad Goals (0)
FTAG and AG = Full Fourth dimension Away Squad Goals (1)
FTR and Res = Full Time Result (H=Home Win, D=Draw, A=Away Win) (A)
HTHG = Half Time Home Team Goals (0)
HTAG = Half Time Away Team Goals (0)
HTR = Half Fourth dimension Result (H=Home Win, D=Describe, A=Away Win) (D)
Referee = Lucifer Referee (J Moss)
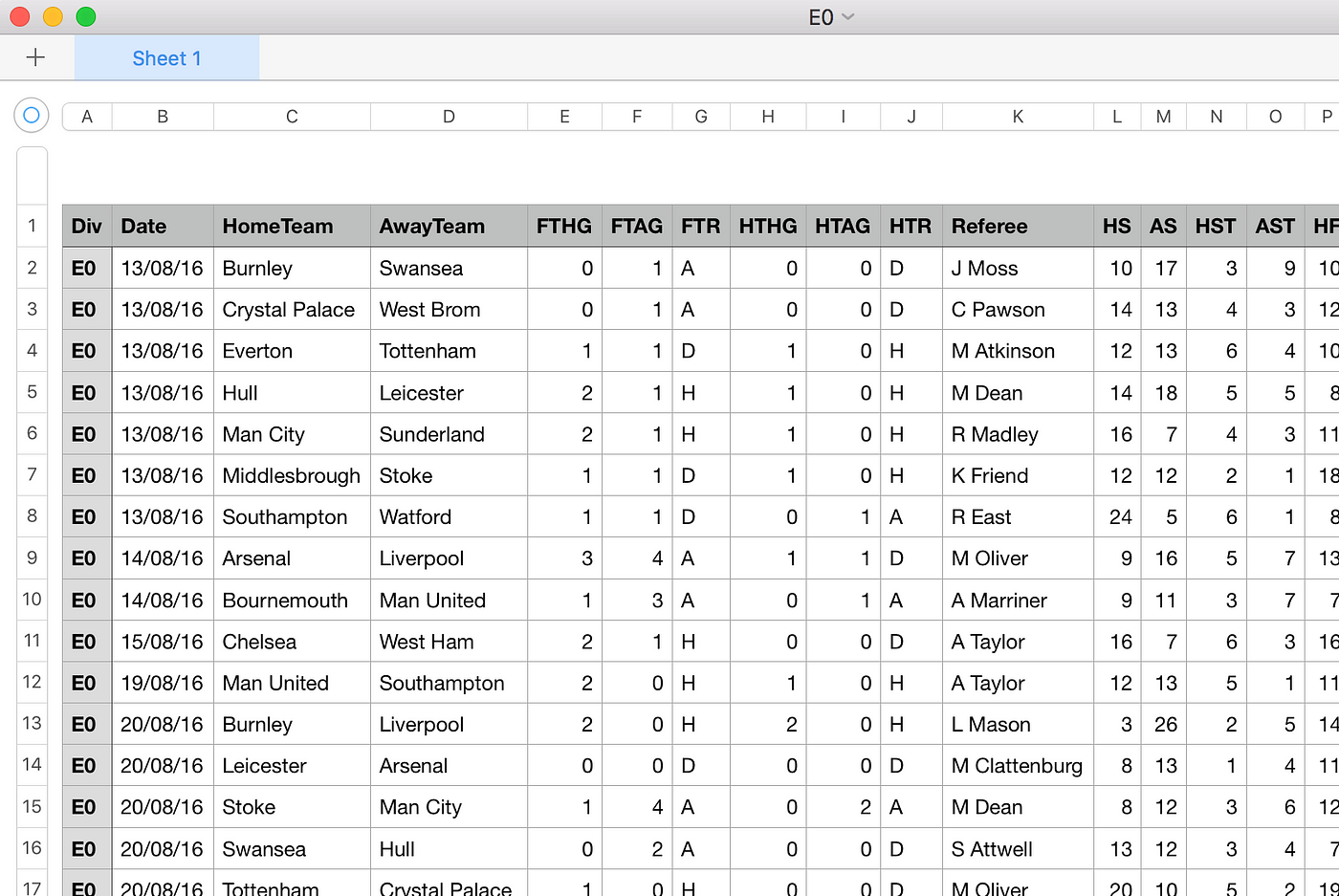
The file looks more or less like this when y'all open it from a spreadsheet programme.
- Detect that the program automatically put the description line as a header row.
- The programme, however, mistakenly split the first column (Div) autonomously from the other columns.
- I rename the file (from
E0.csv) toE02016.csv. Throughout the rest of this article, I will refer to the file using this new name.
Directory Structure
I name this project equally 002_filtering. You tin can name it anything equally you wish. My path for this project is ~/scalaSpark/002_filtering/. I created a separate directory specifically for all raw data to exist read past Spark at ~/scalaSpark/input/. Hither are the summary of relevant directories:
- projection directory :
~/scalaSpark/002_filtering/ - .sbt file :
~/scalaSpark/002_filtering/002filtering.sbt - .scala file :
~/scalaSpark/002_filtering/src/chief/scala/002filtering.scala - E02016.csv :
~/scalaSpark/input/E02016.csv
Setup the .sbt file
Hither are what you lot have to put in the sbt file.
name := "002filtering"
version := "i.0"
scalaVersion := "two.11.8"
libraryDependencies += "org.apache.spark" % "spark-core_2.11" % "2.3.0" - The terminal line :
libraryDependencies += "org.apache.spark" % "spark-core_2.11" % "2.three.0"is Spark dependency. - In this tutorial we will use merely bones RDD functions, thus only
spark-cadreis needed. - The number two.xi refers to version of Scala, which is 2.eleven.x. The number 2.3.0 is Spark version.
Write the Scala lawmaking
Now it is time to write our code to the process the E02016.csv file. We will offset from short codes, and so run, and so add some more codes, and then run, repeatedly. I volition explain the codes along the way.
1. Setup SparkContext
- Create the
002filtering.scalafile and add together these lines to it. - And so relieve the file.
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object filtering002
{
def principal(args: Assortment[String])
{
println("\n\n>>>>> Kickoff OF Program <<<<<\due north\n"); val conf = new SparkConf().setAppName("002filtering")
val sc = new SparkContext(conf); println("\n\northward>>>>> Terminate OF PROGRAM <<<<<\n\n");
}
}
- In line 3 I named the object every bit
filtering002. This is just because the object name cannot start with numbers. - The code begins by importing
SparkContextandSparkConf. SparkConf is basically the configuration parameters of SparkContext. - SparkContext is the class for the Spark world, where your codes are managed and run. You tin refer to the Spark's primary API folio or SparkContext API folio for more information.
- The
val conf = new SparkConf()line creates the configuration for SparkContext. In this example, only 1 parameter,AppName, is defined. - The
val sc = new SparkContext(conf)line creates a SparkContext object using the SparkConf divers. -
valis a Scala reserve word use to declare a new variable. The variables declared withvalis immutable. An immutable variable is a variable that its value cannot exist changed afterward. This similar to a constant in some other languages. It is mutual to use immutable variables in Spark. If we need to alter an immutable variable, we commonly create a new modified immutable one rather than directly modify the existing one. You volition gradually acquire why this is Spark's mode of coding as yous go along. - The two
printlnlines just impress out strings. These are what we expect to run across on the output after running the code.
Run
Although we have not done anything much here, just allow's run to code to make certain things become well so far.
cd ~/scalaSpark/002_filtering # goto project dwelling house
sbt parcel # compile the project ### Wait for the compilation.
### The compilation should end with "Success" ### Then run the spark-submit command below spark-submit ./target/scala-2.11/002filtering_2.11-1.0.jar
- Output of
sbt parcel

- Output of
spark-submit
- From the spark-submit command, you will encounter lines of output.
- You should conspicuously meet the START OF PROGRAM and END OF PROGRAM lines in the output. This indicates that you take washed well and then far.
Now, let'south read the E02016.csv file into Spark and do some interesting things to it.
2. Read .csv file into Spark
- Spark allows you to read several file formats, e.thou., text, csv, xls, and turn it in into an RDD. We then apply series of operations, such as filters, count, or merge, on RDDs to obtain the final outcome.
- To read the file E02016.csv into an RDD, add this line to the scala file.
val logfile = "./../input/E02016.csv"
//OR val logfile = "/Users/luckspark/scalaSpark/input/E02016.csv" val logrdd = sc.textFile(logfile)
- Note that I use the relative path
"./../input/E02016.csv"to refer to the data file. This is the path relative to the location that you run the spark-submit control. For example, I usually execute the spark-submit control at the project directory, which is~/scalaSpark/002_filteringin this case. That is, my location is~/scalaSpark/002_filteringand the file location is~/scalaSpark/input/E02016.csv. Therefore, the relative path from my location to the file is./../input/E2016.csv. If I run the spark-submit command at any other location, file does not exist fault would exist thrown at runtime. - Alternatively, you can use an absolute path instead, every bit I put in the //OR comment line.
- Next, The
sc.textFile()reads thelogfileand catechumen it into an RDD namedlogrdd.
iii. Print elements of an RDD
- 1 of the master reasons for printing out RDD elements is to run into whether the data format or pattern are as what nosotros expected. The raw data is by and large huge and information technology is rare to print ALL elements of an RDD.
- Rather than printing out all elements, using
.take()to print out RDD elements is a good idea. It picks samples of elements for us. Every fourth dimension the code is executed, samples taken are generally the same. This is, nevertheless, not ever, both the data itself or the lodge of the data could be different. - Now that we accept read all lines from
E02016.csvfile onto thelogrddRDD. - Let's impress the
logrddand encounter if the data is correctly read using a combination ofhave,foreach, andprintln, like this
logrdd.take(10).foreach(println) - The dot (
.) is how you connect the methods together. Methods are processed from left to right. The output of the method on the left becomes an input of the side by side method on the right. Hither the output of .have(10)becomes the input to the .foreach(println)method. -
.take(10)accept 10 sample rows from thelogrddRDD and repeatedly print each of them out. - Now, let's epitomize and run the code. Below is the unabridged code with the new lines added.
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object filtering002
{
def primary(args: Array[String])
{
println("\n\n>>>>> START OF Programme <<<<<\due north\n") val conf = new SparkConf().setAppName("002filtering")
val sc = new SparkContext(conf) val logfile = "./../input/E02016.csv"
val logrdd = sc.textFile(logfile) logrdd.take(10).foreach(println) println("\n\n>>>>> END OF PROGRAM <<<<<\n\n")
}
}
- Re-compile and run the code using the same commands:
sbt packagesospark-submit ./target/scala-2.11/002filtering_2.11–1.0.jar - The output is shown beneath.
- At the very end, above the
End OF Programstring, y'all shall see the contents of theE02016.csvdisplayed.
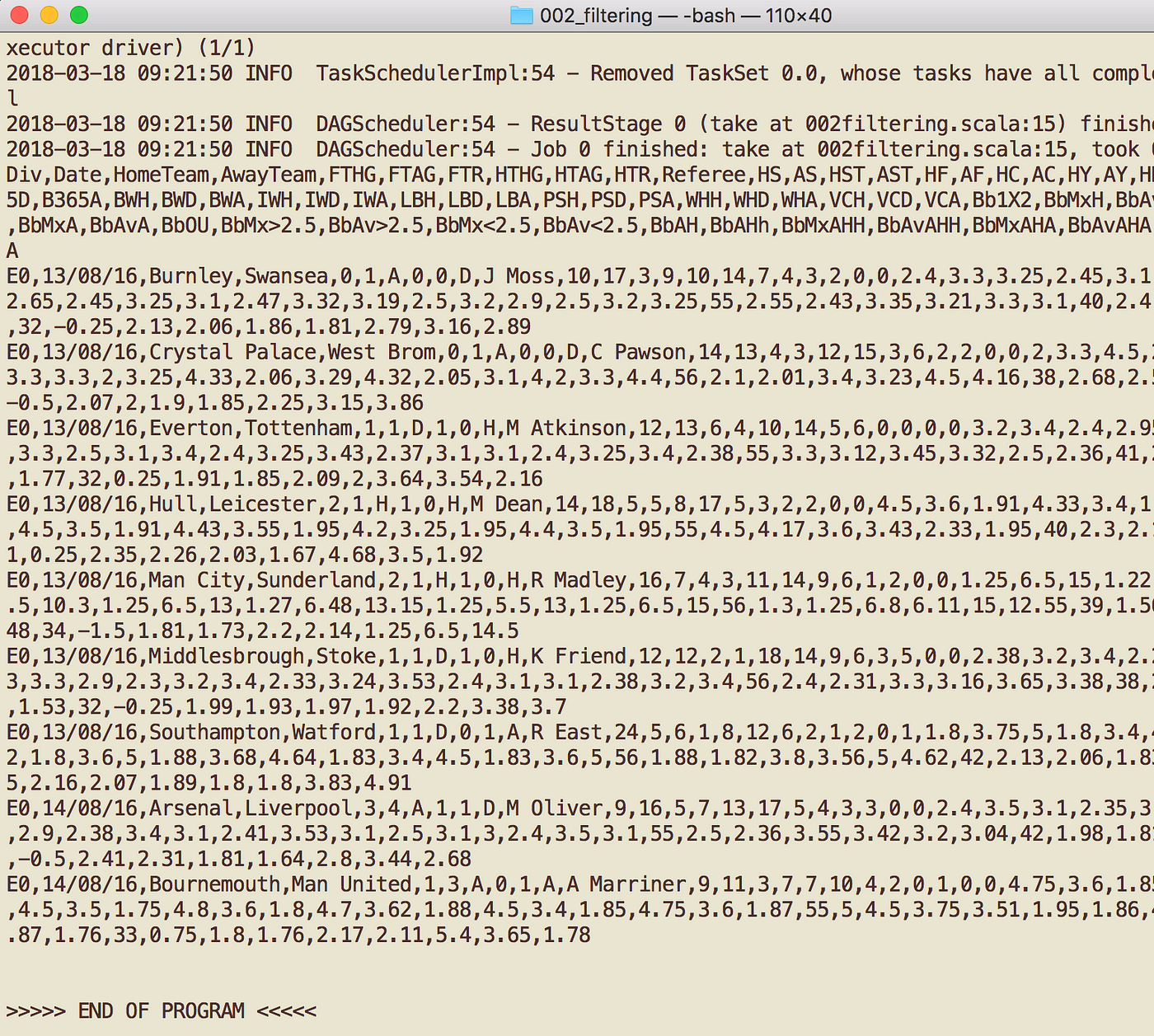
- Allow'due south compare information technology with the information displayed in text editor.
iv. Information pick past row using .filter( )
At present, as you lot tin can see, in that location are too much data. Let'south filter something out to brand things more meaningful.
First, let'south filter out the header row. This is obvious since it is mixed with the data and would definitely crusade errors to assay outcomes. For example, if we wish to count the total number of matches played in the season, since the information is one match per line, simply counting the number of lines would requite us the answer. This would, however, mistakenly include the header line in the counting, giving out the answer of 381 rather than 380 matches per flavor. This is clearly undesirable. Thus, let'south discard the header row now.
- Yous tin can select to filter out rows by criteria using
.filter() - Let's try this code.
val f1 = logrdd.filter(s => southward.contains("E0"))
f1.accept(10).foreach(println) - In human linguistic communication, the
val f1 = logrdd.filter(s => s.contains("E0"))would read, "copy every chemical element oflogrddRDD that contains a string "E0" equally new elements in a new RDD namedf1". - The second line merely print samples of the new
f1RDD (that just containsE0in the line). - In details, the code first define a new RDD named
f1. - Then it reads all elements of the
logrddRDD and applies the benchmark of the filter to it. - The
sins => s.contains()represents each element of the logrdd RDD. - You lot can replace both
southwardwith whatever other messages or strings you lot wish. The most ordinarily seen in Spark earth isline, i.due east.,.filter(line => line.contains("E0"). - Algorithmically, I choose the string "
E0" because the header line is the only line without such cord. Try it yourself with other strings.
Let's epitomize and run the lawmaking.
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object filtering002
{
def chief(args: Array[String])
{
println("\n\n>>>>> Offset OF Programme <<<<<\northward\n") val conf = new SparkConf().setAppName("002filtering")
val sc = new SparkContext(conf) val logfile = "./../input/E02016.csv"
val logrdd = sc.textFile(logfile) logrdd.take(10).foreach(println) val f1 = logrdd.filter(south => s.contains("E0"))
f1.take(10).foreach(println) println("\n\n>>>>> END OF Plan <<<<<\n\n")
}
}
- From the output, yous will find 2 sets of data printed out, ane from
logrddand the other one fromf1. Noticef1does not contain the header line any more than.
5. Using Not with .contains( )
In the previous topic we have covered the .filter(southward => s..contains()) in which we choose to keep every lines containing "E0". How nigh if we wish to go on lines that "do not contain something"?
To exercise this, we add together the "Not", which is !, into the argument. It is a bit tricky where to put the ! sign, thus I think information technology is worth mentioning information technology here.
- Beneath is a argument to proceed lines that practise not contain a string "FTHG".
val f2 = logrdd.filter(s => !(south.contains("FTHG"))) - Find the position of the
!and adjacent fourth dimension you can utilise it correctly. - Try this line of lawmaking and yous shall get the same outcome as in the previous topic.
half-dozen. Count the number of elements in an RDD
From the previous section, nosotros discarded the header line and there were no header lined printed out from the f1.accept(x).foreach(println)line. Withal, equally I explained before that the take(x) only takes some samples of RDD elements, is information technology possible that perhaps the header line is nevertheless there but just had not been sampled? Let's count the lines to help verifying this.
-
.count()method is Spark'southward action. It counts the number of elements of an RDD. - It returns a Long integer. Therefore, we can only impress it out.
println(logrdd.count() + " " + f1.count()) - Here I print the count of
logrddRDD get-go, add together a space, then follow by the count off1RDD. - The entire code is shown again here (with simply i line added from the previous i).
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object filtering002
{
def main(args: Assortment[String])
{
println("\n\n>>>>> Commencement OF Program <<<<<\n\north") val conf = new SparkConf().setAppName("002filtering")
val sc = new SparkContext(conf) val logfile = "./../input/E02016.csv"
val logrdd = sc.textFile(logfile) logrdd.take(10).foreach(println) val f1 = logrdd.filter(s => s.contains("E0"))
f1.take(10).foreach(println) println(logrdd.count() + " " + f1.count()) println("\n\n>>>>> Finish OF PROGRAM <<<<<\n\due north")
}
}
- Subsequently you run information technology, you shall see the "
381 380" line, merely above the End OF PROGRAM string, as shown below.
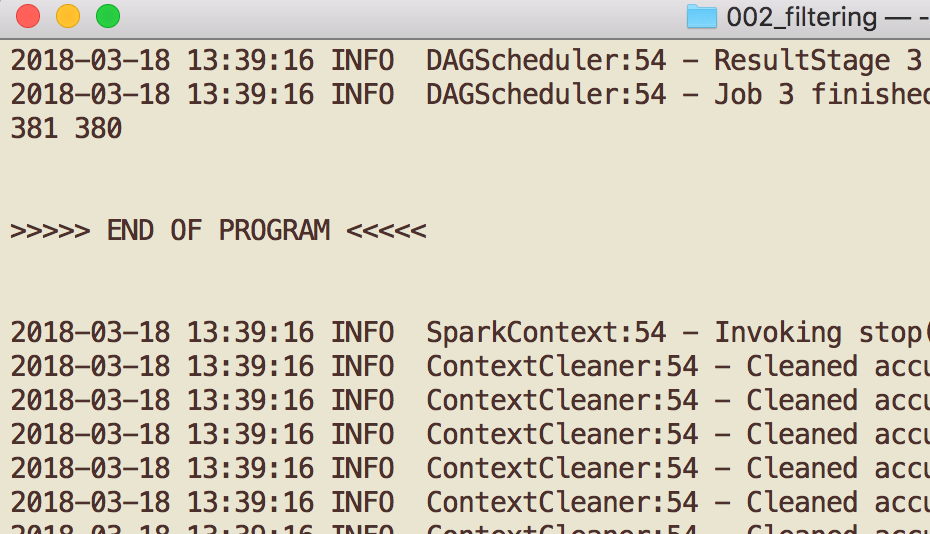
There you go, now you lot know that 1 line of data is discarded (presumably, the header line).
7. Print all elements of an RDD
For some, counting the number of lines of the f1 RDD may be non enough to prove that the header line has really been removed. How most printing out all elements of the f1 RDD?
- Printing out all elements of an RDD is a bit tricky.
- At this stage, you can look at an RDD equally information technology is an Assortment, with one of import exception — it is distributed . Spark is designed to be run on a large number of machines where data are divided and distributed among them. The data could even be divided into several partitions in one machine. For example, if you lot have 100 rows of data, perhaps the first 10 are given to the first machine, the next 10 are given to the other machine, so on.
- When press out, spark use machines' stdout. Differeent machien means dissimilar stdout.
- In local mode, information technology is ok to print out using
-
f1.foreach(println)ORf1.take(f1.count().toInt).foreach(println) -
have()expects anIntinteger as a parameter butcount()returns aLonginteger. Thus, the.toIntmethod is needed hither. - If yous wish to print the exact element of the RDD, e.1000, something like printing out the value at the alphabetize i of an Array, yous accept to convert the RDD to a local assortment using .
collect()method. The array returned volition exist stored on 1 motorcar (the driver auto), significant that it is non a distributed dataset whatsoever more. This .collect()could cause errors if the local automobile has bereft amount of memory to hold the entire set of data. - In cluster way where the driver and the executor machines are different, outputs of the print command will exist displayed on each auto'southward
stdout. Therefore, you volition not see all outputs at the driver node. That is, if you try to print all elements of an RDD, yous will not run across all outputs from the commuter automobile. Usingcollect()fixes the problem if you lot have sufficient retentivity at the driver node.
8. Effort it yourself
Let'due south epitomize what y'all have learnt:
- read from file to RDD using
.textFile() - sample and print elements of RDD using
.take() - filter data using
.filter()and.contains() - using Non with
.contains() - count the number of RDD elements using
.count()
Here are some interesting things you are able to do using methods you accept learnt. Try it out yourself.
- Print and count but the Liverpool matches (i.due east., 20 matches).
- Print and count only the Liverpool vs Chelsea matches (i.due east., just 2 matches).
- Print and count simply matches that Liverpool won.
- Print only matches played in Nov.
- Count the number of matches that Liverpool lost before the new year's day (of that season)
That'due south all for this tutorial. Peace.
Source: https://medium.com/luckspark/spark-tutorial-2-using-filter-and-count-63400604f09e
0 Response to "Prints Out the Count of Records Read Spark"
Enregistrer un commentaire